How I Wrote A Kinesis Trigger Plugin For Spin
 Darwin Boersma
Darwin Boersma
spin
rust
kinesis
aws
plugins

Hi there! My name is Darwin and I have worked on microservice architectures of various shapes and sizes throughout my career (Docker-in-Docker, AWS Lambda). I recently became a member of the Spin community and contributed an AWS Kinesis trigger – I’d love to share a bit about why. I have worked on many data pipelines where consistency is important. On the extreme end, when your entire product is providing quality data, you care a lot whether your data gets from point A to point B. But how do you ensure that happens? Platforms like Kafka are purpose-built for this use-case, offering guarantees on durability and receipt of data that would be difficult to replicate. Kinesis is the AWS cloud solution to this problem.
My Introduction To Spin
A common approach to creating real-time data pipelines in AWS is using Lambda functions to parse data from Kinesis – the function will be triggered quickly after data is added to the Kinesis stream and this solution offers complete flexibility on how you process data. This approach works well – function-as-a-service* frameworks have numerous benefits.
* Function-as-a-service generally offers: automatically scale to zero at low volume, automatically scale up rapidly under load, integrate with distributed services (like Kinesis), compose code across languages with low effort. You can learn more about FaaS in Fermyon’s Serverless Guide
But, serverless options like Lambda still have challenges:
- Scaling causes unpredictable cold starts as VMs are spun up for function executions. Later in a project lifetime, cold starts can become an insurmountable barrier due to new requirements, causing teams to undertake additional effort to migrate code to hosted servers.
- Testing and observability require significant additional effort – many tried-and-true debugging mechanisms are unusable. Tracking call chains across an application requires configuration in the code for each microservice. Running a function locally is highly restrictive, and many resources cannot be spun up locally.
- Function executions cannot share resources (e.g. connection pools) – cold executions must create new connections to external resources with all the associated cost.
How do we keep the advantages of serverless architecture but fix these pain points? Well, Webassembly (Wasm) is proving to be a compelling foundational technology for the next generation of serverless architectures. Fermyon has been very interesting to follow as a pioneer in this space – Fermyon Spin is powered by the efficiency and security of Wasm.
If you aren’t familiar with server-side Wasm, no worries - you don’t have to be an expert! Here are a few reasons why Spin stands out to me as a developer tool for writing event-driven functions powered by Wasm.
- Upleveling performance with polyglot capabilities - Spin lets your Python/JavaScript services seamlessly invoke efficient Rust code.
- Portable dependency injection – Invoke a SQLite database locally, invoke a distributed SQL service when deployed to the cloud – without requiring any modifications to the application’s source code.
- Observability with batteries included - If you have a current set of observability tools built on the wonderful, open-source OTel ecosystem, Spin has been making rapid advances to fit into your existing developer toolkit. Recently, as of Spin 2.4, experimental OTel integration was released as well as a powerful testing framework.
- Extensible - Spin has an extensible plugin model that makes it easy to connect your Spin applications to external dependencies. HTTP and Redis triggers in Spin are excellent – and the folks at Spin have kindly published an SQS trigger providing a model for AWS integration!
Having worked with AWS Kinesis Lambda event sources and guarantees this model offers that enable high volume data processing, I wanted to take a crack at providing a similar integration of Kinesis for Spin. I am excited to see Spin and Wasm supercharge stream processing and serverless data pipelines!
How The Kinesis Trigger Works
Kinesis streams are generally used for high-volume, rapid data transfer. Common use cases are processing large quantities of data + metrics, syncing updates between databases in real time (also known as change data capture), and durably storing events for replay. The Spin Kinesis trigger aims to replicate the ease of consuming Kinesis data inside AWS cloud via Fermyon Spin applications – if you are familiar with creating a Lambda handler for Kinesis, you will be right at home creating a Spin handler for Kinesis. The WIT interface for consuming data is modeled directly after the Kinesis API – like the AWS Lambda event source, your handler simply takes in a list of records (link to full example).
async fn handle_batch_records(records: Vec<KinesisRecord>)-> Result(), Error> {
for record in records {
// do something with each record
}
}
The Kinesis trigger guarantees that data in each shard will be processed in sequential batches, and that each shard will be processed independently. High-volume, ordered data processing in Spin with Kinesis!
Kinesis Trigger In Action
Now that we’ve built up some context on how to consume Kinesis data, let’s walk through how you can set this up on your own Spin application.
Prerequisites: You will need a provisioned AWS Kinesis instance (tutorial) and have installed Spin
Using this plugin requires only a few simple steps:
- Install the plugin
spin plugins update
spin plugins install trigger-kinesis
- Install the template
spin templates install --update --git https://github.com/ogghead/spin-trigger-kinesis
- Create your Spin application with the Spin CLI using the template, filling out the require parameters
Note that only the ARN parameter is required. The remaining are set with the following defaults
spin new -t kinesis-rust hello_kinesis
Description: Simple spin app that handles kinesis events
ARN: rn:aws:kinesis:us-east-1:123456789012:stream/TestStream
Batch Size: 10
Shard Idle Wait Millis (ms): 1000
Detector Poll Millis (ms): 30000
Shard Iterator Type: LATEST
- Implement your component’s business logic to handle the Kinesis event data (for example, in Rust)
use spin_kinesis_sdk::{kinesis_component, Error, KinesisRecord};
#[kinesis_component]
async fn handle_batch_records(records: Vec<KinesisRecord>) -> Result<(), Error> {
for record in records {
// Process the record
}
Ok(())
}
- Build and run your Spin application to begin handling Kinesis events
spin build --up
Congratulations! You now have a running Spin application that’s ready to begin handling Kinesis events.
So how does it perform? In version 0.3, I instrumented the trigger with OTel support, generated mock data for Kinesis, and gave the Kinesis trigger a spin:
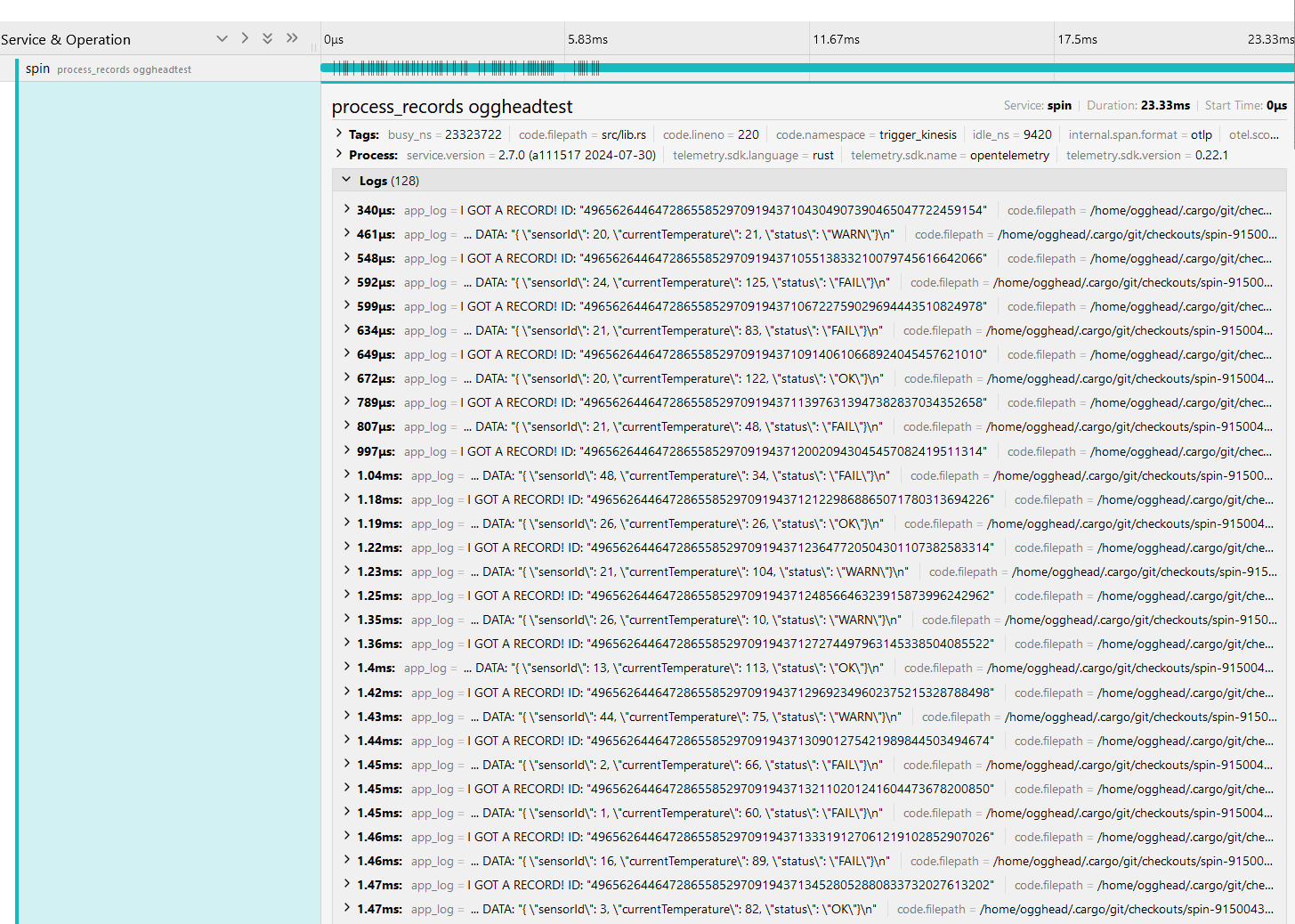
Whoa! The component is spinning up and beginning processing in under a millisecond. This batch of records is processed in 23 milliseconds – pretty cool.
* For a full accounting of performance, I want to test a component involving network connections, and compare a replica Lambda function. Testing under ramping load, at variable load, and with rapid spikes would also help to give a more full picture. That is a story to tell another day – stay tuned!
Publishing and Distributing
Before we wrap up, I’d be remiss if I didn’t share a bit about my experience authoring a Spin plugin. Creating and publishing a plugin was refreshingly streamlined! By referring to the SQS trigger published by Spin, I answered a few questions for myself, and hopefully someone else too.
Q: How does a trigger read in spin.toml configuration?
A: Structs and a trait! The setup is short, idiomatic Rust.
#[derive(Clone, Debug, Default, Deserialize, Serialize)]
#[serde(deny_unknown_fields)]
pub struct FooTriggerConfig {
pub component: String,
pub foo_custom_field_1: String,
pub foo_custom_field_2: Option<u16>,
}
#[derive(Clone, Debug)]
struct Component {
pub id: String,
pub foo_custom_field_1: String,
pub foo_custom_field_2: Option<u16>,
}
#[async_trait]
impl<F; RuntimeFactors> Trigger<F> for FooTrigger {
const TYPE: &'static str = "footrigger";
type CliArgs = NoCliArgs;
…
async fn new(_cli_args: Self::CliArgs, app: &App) -> Result<Self> {
let queue_components = app
.trigger_configs<FooTrigger>(<Self as Trigger<F>>::Type)?
.into_iter()
.map(|(_, config)| Component {
id: config.component,
foo_custom_field_1: config.foo_custom_field_1,
foo_custom_field_2: config.foo_custom_field_2.unwrap_or(10),
})
.collect();
Ok(Self { queue_components })
}
}
Q: How does a trigger execute components?
A: Here is an example setup!
async fn execute_wasm(&self, data: &FooData) -> Result<()> {
let component_id = &self.component_id;
let instance_builder = self.app.prepare(component_id)?;
let (instance, mut store) = instance_builder.instantiate(()).await?; // Spin prepares instance of component to execute
let instance = SpinFoo::new(&mut store, &instance)?; // Create an instance of WASI interface, using Spin component to satisfy the interface
match instance
.call_handle_foo(&mut store, records) // Run the Spin component!
.await {
// Handle response from Spin component
}
}
After cleaning up, testing, and merging a branch with the Kinesis changes into my repository’s main branch, I followed the steps to create a pull request to the spin-plugins repository – and that’s it. The Kinesis trigger plugin is now available for download!
What’s Next
I am still working on enhancements to the trigger, and I plan to continue to release incremental updates to it. For version 0.3, I have added support for all shard iterator types as well as OTel integration through the excellent Spin OTel plugin. Contributions are welcome big and small; Fermyon’s own MacKenzie made the plugin even better by adding template support for Rust components too!
AWS has a lot of distributed services and we have only scratched the surface on the integrations possible with Spin – what would a DynamoDB Streams trigger look like? How about EventBridge? S3? There are many possibilities. Spin offers the prospect of pluggable interfaces enabling developers to utilize cloud services or local services seamlessly, and lays the foundations for a new type of developer experience. If you’re curious on how to create a plugin, the Spin documentation is excellent and the folks at Spin are very welcoming over at Discord.
Creating this plugin has been a lot of fun. I hope that it helps to demystify Spin for some other folks, as it has for me. I am online at darwin@sadlark.com – shoot me a message if you’re curious about the plugin, my experience with Spin, or anything else tech related!