Move Over SEO, It's Time For AIO
 Matt Butcher
Matt Butcher
seo
ai
llm
aio
genai
generative ai

AI isn’t going to save the world, but it’s going to fundamentally change search. And those of us who care about the findability of our information need to start thinking about how AI training and inferencing is influenced by the content we generate. SEO is not the future. AI Optimization (AIO) is.
The Premise: Search Is Dead
I was at lunch with a software engineer friend from Oracle, and we were chatting about how we didn’t use search as much. As we talked, we uncovered two patterns to our search engine usage.
Pattern 1: “I remember this article (or site, or something)… where was it?” For that, we still used standard search engines.
Pattern 2: “I have this question, and I just want an answer.” And for that, search was a multi-step process:
- Start with the question
- Try to distill it to search terms (to reduce noise)
- Click on links until finding one that has a likely answer
- Sometimes repeat this process
Each of us had arrived at the conclusion that generative AI offered a better experience. Why hunt for information when something could merely generate an answer for us? For timely information I’ve found Perplexity useful and timely, so this article uses Perplexity as a reference point.
How Good is the Answer?
As content providers, we all had a tried-and-true playbook for SEO, involving everything from robots.txt to structuring our HTML to generating the right kind of text. Obviously, a lot of that is the same for AI crawlers (assuming they don’t all decide to ignore robots.txt). But we certainly need to rethink some of our assumptions.
For an example of this, let’s look at how Perplexity answers the question “What is Fermyon?” It is an example of a “Pattern 2” question. Moreover, this is the sort of query that I, as a content producer for Fermyon, care deeply about. I want Perplexity to produce a high quality answer that reflects who we actually are and what we do.
I ran all queries in a logged out state, and used the “New Thread” button whenever starting a new thread.
Here’s what it produces:
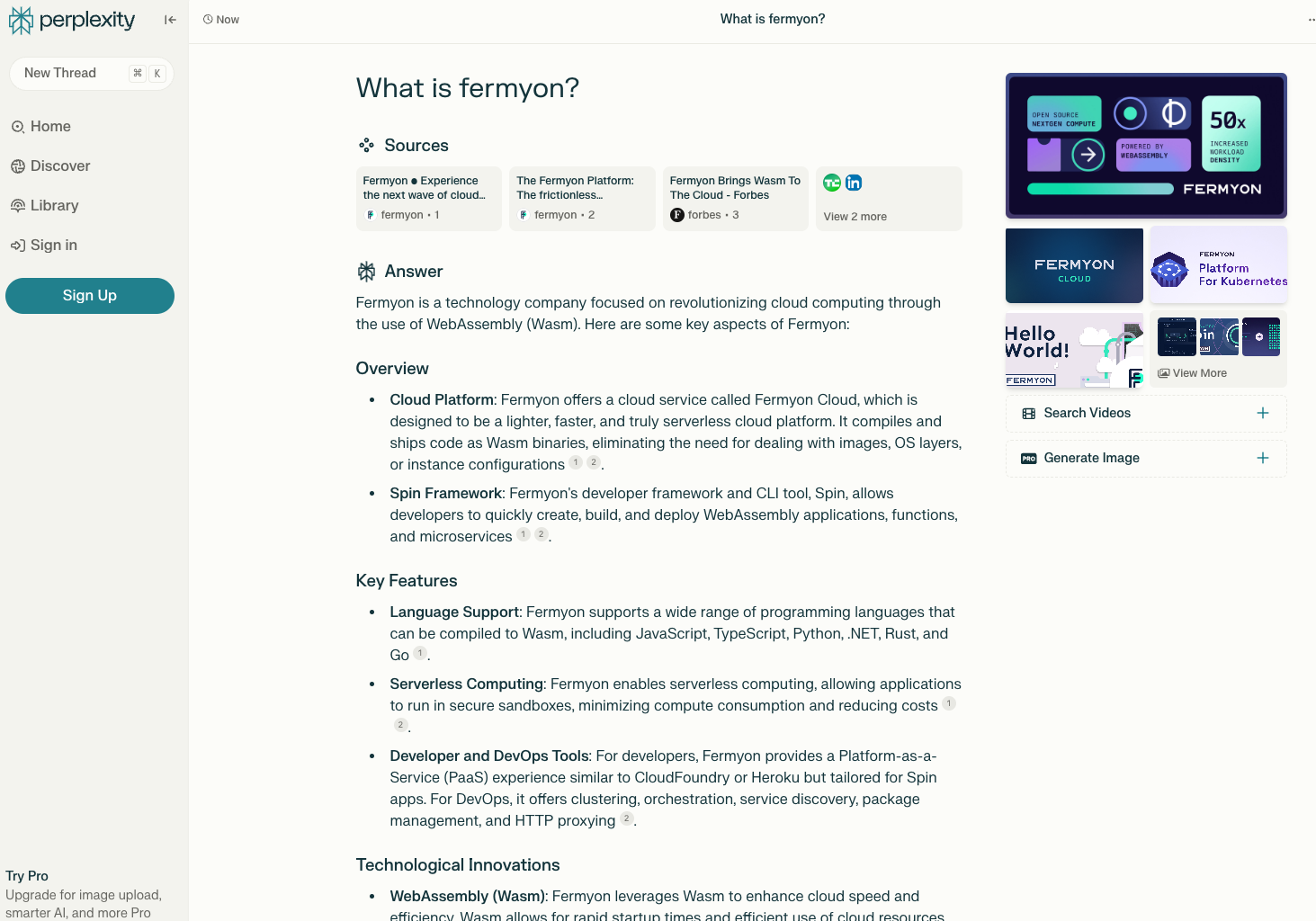
The above shows high fidelity content that is representative of our core messaging. It didn’t exactly regurgitate our “Pioneering the Next Wave of Cloud Computing” tagline or replicate many of the phrases we frequently use (“From blinking cursor to deployed application in two minutes or less”). But it certainly conveyed those ideas.
It listed two of our products in the overview (Fermyon Cloud and Spin). The Key Features section is accurate and is actually a reasonable facsimile of what we usually tell our customers. Lower on the page, it did talk about SpinKube as well. But our product Fermyon Platform only got picked up in the sidebar images (which we cover more later).
Every time the question is asked, a new answer is generated. I did run the query a few different times, and the information was different on each run. The conclusions I have derived here, though, were generally observed in each repeated query.
As a follow-on, I asked, “What is Spin?” inside of the same session.
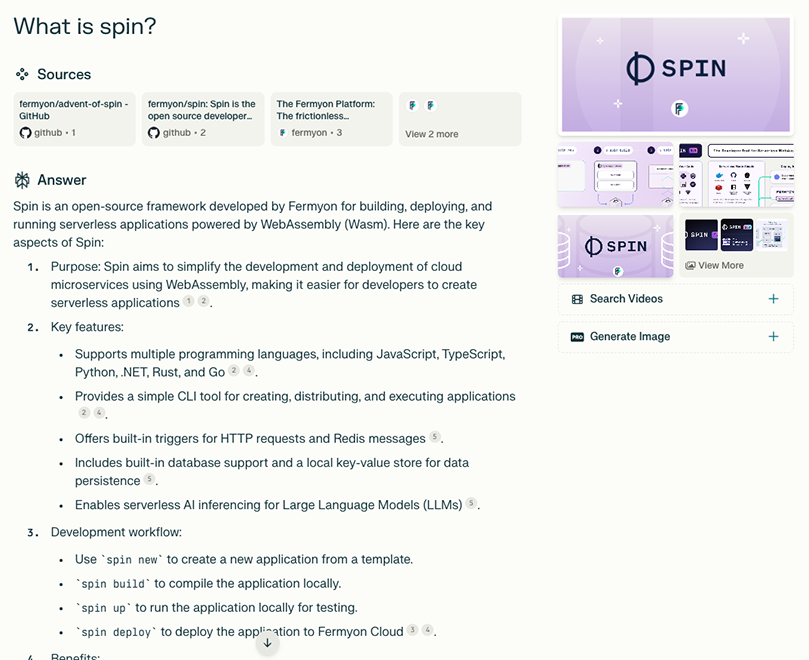
The “What is Spin?” question would have been too generic if asked in a new session. I might just as likely have been given an answer about physics or politics. But asked in the context of the previous Fermyon question, Perplexity generated an answer about Fermyon Spin, and again the answer was very good.
I was surprised at how accurate and valuable the results were. It even walks through the developer workflow. This is exactly the kind of content I would want to provide to a newcomer in our target market (cloud developers).
It’s time to learn from what we’ve just seen.
The Big Questions of AI Optimization
For our two queries, the quality of Perplexity’s answers were great. That was not something that I observed uniformly across all the companies I tested with. Clearly, Perplexity’s quality is influenced by what information it consumes.
There are three things to consider when looking at optimizing for AI.
- Sources: Where is the crawler getting its information (and how is it prioritizing sources)?
- Language and tone: What sort of language is it using in the answer? (A question related to audience)
- Media: What non-text information surfaces?
Let’s dive into each of these.
Information Sources
The most important thing we can learn from the answers we saw above is where Perplexity got its information. The here are three pieces of good news here:
- Some citations are from
fermyon.com, developer.fermyon.com and our GitHub and LinkedIn pages, which means we have a direct avenue to influencing the model
- Other citations are from high-fidelity relevant sources (Forbes and TechCrunch), which are respected sources of unbiased information
- None of the citations are from competitors or content farms, which would be low-fidelity sources about our query
Above, we asked “What is Spin?” And I mentioned that I was surprised to see that it produced an accurate developer workflow. Where did it get that information?
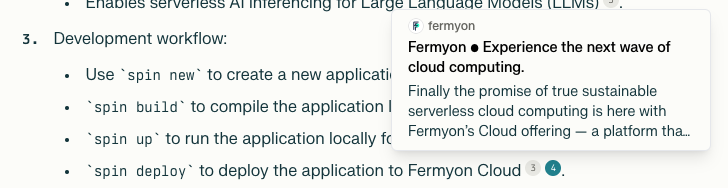
Our homepage! Nothing drives home the importance of good messaging like the LLM preferring homepage content. One of our most important messages has been that Spin is super easy to use, and you can get started in just four easy steps. Having that workflow on the Fermyon landing page, and in a way that was easily parseable to the LLM, means that we see it presented clearly by Perplexity.
I tested this on multiple companies: The content on the home page is very much prioritized in answers Perplexity generates.
On external sources, I’ll come clean: We worked hard to get those articles published in TechCrunch and Forbes. At the time those articles were written, we were focusing on particular press announcements. We didn’t realize, though, that those articles would be used for training LLMs. It worked out to our benefit. But my key takeaway is that one important part of AIO is getting covered by high-fidelity media outlets, and making sure that our messaging to those outlets is consistent with long term vision.
Other companies I tested did not get the benefit of top-tier media recognition. Sometimes user-driven content sites like Reddit were listed in the sources. This showed in the quality of the answers Perplexity delivered. The descriptions on those pages were notably less informative, less detailed, and less accurate.
The third point, though, is something you want to watch out for. I did find a case where an AI startup was competing against an offering from AWS. When querying Perplexity about that startup, Amazon’s page was cited more than the startup’s own homepage. And the result was that the opening paragraph pointed away from the startup’s offering and toward a general thing.
Language Used in Answering
Many years ago, back when semantic networking was the cool new AI technology, I worked at WebMD on a semantically aware search. The issue: healthcare has a few different jargons. First is the highly technical jargon used in medical journals, heavily relying upon Greek and Latin vocabulary (myocardial infarction). Second, there is the partially technical language used in health related popular publications (cardiac arrest). Finally, there is lay jargon that many of us employ (heart attack). We tried to build semantic mappings that would “translate” the more technical languages into lay terminology. We wanted to translate from “doctor talk” to “patient talk.” (Spoiler: We didn’t solve the problem.)
But I learned an important lesson about vocabulary, tone, and structure. These conventions reflect the community reading and writing the material. For us as engineers, this is all too familiar. I regularly write on this site about how we’re writing Spin, the serverless WebAssembly tool that boasts high density and ultra-fast performance. But when a family member asks what I do, I say, “I build tools to make the cloud faster.“
LLMs generate output text that is similar to the texts it ingests. So the way you write your question can influence the language used in generating the answer. If you’d like to see this in action, ask Perplexity “What is myocardial infarction.” Then (in a new session) ask, “what is a heart attack?”
For me, the answer to the first query said things like this: “It occurs in the mid-portion of the heart muscle wall, between the subendocardial (inner) and subepicardial (outer) layers,” while the second query generated a text that was mostly devoid of technical terminology (with the serendipitous appearance of the phrase “also known as a myocardial infarction”) and appears to be written with a lay person in mind:

The takeaway from this is that we need to be mindful of our tone, vocabulary, and references when we write our content. When we produce content or even seek to get others to produce content on our behalf (viz. the TechCrunch and Forbes articles cited by Perplexity), we want to do our best to ensure that the language used is targeted toward our desired audience.
The Jargon Corollary
Interestingly, there’s a second conclusion to be drawn: If we use overly specialized jargon that is not broadly understood, we might stunt the LLM’s ability to generate relevant text. The LLM functions by finding words in proximity to the original sources. I ran a query on a technology company that uses a lot of highly specialized jargon that they coined, and is not broadly used outside of their product. The resulting Perplexity output was vague, confusing, and (in a somewhat humorous turn) actually cited the Mariam-Webster Dictionary as one of its input sources. Their vocabulary was too niche for the LLM to generate meaningful output.
Images, Videos, and Other Content
At Fermyon, we’ve worked hard to present a strong visual brand identity, as well as embracing a variety of media. I am surprised to see what surfaces (lots of images, some YouTube videos) and what did not (any of the bazillions of podcasts I have been on).
An earlier screenshot shows the images on the right-hand side with a “Search Videos” button beneath. I clicked that button as well, and this is what I see in that right-hand column:

The first section is several images from our website. Some of those are twitter cards embedded in blog posts, while others are from documentation. This is good information, as it leads to the discovery that Perplexity is using images from meta content in the HTML head.
The videos are all from YouTube. Two come from our YouTube channel — again, good evidence that we have some direct influence over the LLM. One comes from a popular developer advocate, Rawkode, and the remaining one is from the Linux Foundation’s Open Source Summit conference. That image links to a talk by Mikkel, Fermyon’s head of product. Once again, our own messaging had a strong impact on the LLM’s presentation.
I ran a few similar queries against other startups, and was surprised to see that for many of them, Perplexity displayed no image or video content at all, even though their websites had plenty of visual media.
It appears to me that the reason is related more to classic SEO: They were not following best practices annotating their media. Likewise, I noticed that the videos that showed up in our video search were ones that we had referenced in our own content.
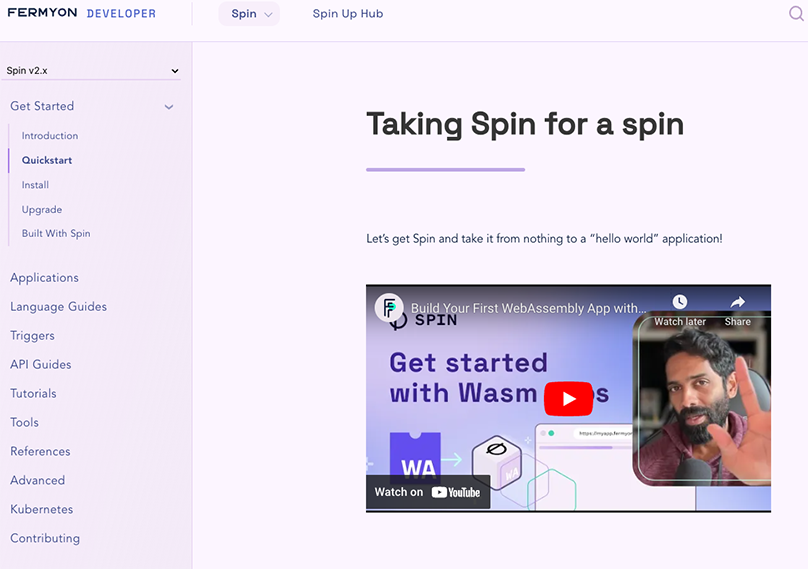
So it appears some additional weight was given to cross-linking regardless of the actual content of that media.
In some subsequent tests, I did discover that Perplexity uses at least the transcript feature of some YouTube videos. That is, it will cite a YouTube video and seemingly draw the content from the transcript. In all my tests, though, I only found one instance of this, and it was for a startup that is very small and had few other sources of information available. So perhaps YouTube transcripts are not considered a high fidelity source.
We’ve taken a first crack at understanding AI and attempting to optimize for it. Before concluding, I thought I’d toss in a few other things I observed.
A Few Arbitrary Observations
I tested over a dozen other companies, and while I am not going to “out” those that performed badly, I did learn a few interesting tidbits:
- Pivoting: One company pivoted products a year ago. Perplexity generated descriptions that seemed to be either tilted toward the older product or an amalgamation of the old and new. This seemed largely related to the content for the older product still being available online.
- Fake Products: One company I tested has a habit of “claiming namespaces” on GitHub, but not actually building those as products. This confused Perplexity, which listed their empty GitHub repos as company products.
- Multiple Domains: There seems to be some advantage to having docs on a separate domain from the main website. It seems that Perplexity limits its number of input sources to something around 5, and prioritizes company domains. So, for example, companies with both a main and docs site seemed to get two of the five source slots allocated.
- The Wikipedia Curse: I found a case where a startup had a Wikipedia page (which was not technical) and thus the entire answer was non-technical — a good warning that the vocabulary used for input strongly colors the output. This led me to test on other companies that I knew had a Wikipedia page, and I saw this pattern repeat in those cases as well. For example, you can try RedHat. Instead of getting deep content aimed at a target audience, Perplexity answers that used Wikipedia were high-level, non-commercial, and non-technical.
- X vs. Y: Sadly, in questions like “compare X to Y,” Perplexity uses vendors’ comparison pages as input. If one vendor has a comparison page and another does not, the results can be skewed. This unfortunately incentivizes bad vendor behavior.
Conclusion
AI certainly didn’t live up to the hype surrounding it last year, but it is gnawing away at a technology that has been at the core of the web since its early days: Search engines.
That means we need to take a cold, hard look at how we optimize our content for ingestion by LLM-training crawlers.
Using Perplexity as an example, I walked through a few things that seem to be keys to getting good AIO:
- Seed the right sources. Your website, your GitHub, social media, big tech mags… all of these are good places to focus for content development
- Watch your language. An LLM is going to generate output that is linguistically similar to the input it ingests. Use that to your advantage – and avoid coining specialized jargon without also providing really good definitions.
- Media matters. Make sure you still SEO and cross-link your images and videos. I was unable to determine whether the text therein had any impact, but Perplexity’s presentation certainly favors those who SEO their media.
SEO still matters, and well SEO’d content seems to do well in AIO as well. But as we get more and more comfortable asking LLMs instead of querying search engines, it will behoove us to think about the LLM when we generate our content.