Scaling Smarter: Maximizing Density and Efficiency with Fermyon Platform for Kubernetes and GKE Autopilot
 MacKenzie Adam
MacKenzie Adam
platform
scaling
kubernetes
Achieving optimal autoscaling is no easy feat. It requires a delicate balance between maintaining high availability and controlling costs. Over-provisioning resources can guarantee uptime but often leads to inflated expenses due to underutilized infrastructure. On the flip side, under-provisioning can result in performance bottlenecks and service disruptions. Striking the right balance is a challenge, both from an operational and cost perspective.
Scaling Smarter: Maximizing Density and Efficiency with Fermyon Platform for Kubernetes and GKE Autopilot
By combining Google Kubernetes Engine (GKE) Autopilot’s container-optimized compute platform capacity right-sizing capabilities with Fermyon’s Platform for Kubernetes high-density, WebAssembly-based runtime, you can achieve exceptional performance while optimizing costs—without the operational overhead of traditional containerized architectures.
The Challenge of Scaling Efficiently
The core challenge in autoscaling lies in accurately right-sizing CPU and memory allocations at the pod level. Ideally, resource utilization should closely match requested resources to minimize waste. Traditional containerized applications introduce inefficiencies due to additional layers that complicate precise resource estimation. This misalignment creates difficulties for cluster administrators attempting effective bin packing, especially when pods lack defined resource limits.
Additionally, demand-based downscaling carries risks. If pods require extended provisioning times, unexpected traffic surges can lead to latency issues or service degradation. The result? A significant gap between peak and average resource utilization, often leading to unnecessary cost and operational complexity.
The Solution: Resource Efficient Applications & Runtime Meets Dynamic Kubernetes Autoscaling
This is where GKE Autopilot and Fermyon’s Platform for Kubernetes shine. By integrating these two technologies, organizations can significantly reduce the gap between peak and average utilization while improving application performance and efficiency.
At the application layer, Spin, the developer tool for writing event-driven serverless applications, provides a lightweight, efficient, and secure execution environment. Spin applications have smaller footprints and faster startup times compared to traditional containers, enabling rapid scaling and reduced resource consumption. This efficiency mitigates the need for over-provisioning, leading to better resource utilization and lower costs.
Bringing WebAssembly to Kubernetes
You might be wondering: how do we integrate WebAssembly seamlessly into a Kubernetes cluster?
Enter SpinKube—an open-source project (part of the CNCF ecosystem) for deploying and managing Spin applications as custom resources within Kubernetes environments. By leveraging SpinKube, developers can easily deploy and operate Spin applications in a Kubernetes-native manner.
Leveraging these capabilities from SpinKube, Fermyon’s Platform for Kubernetes, provides a robust, user-friendly serverless platform that enables high-density Spin app deployments. With Platform for Kubernetes, developers can run thousands of applications per node—nearly 10 times the existing pod limit in Kubernetes.
High-Density Compute Meets Responsive Scaling
When combined with GKE Autopilot, which offers low latency pod scale-out within seconds (scaling workloads more than twice as quickly with their optimized HPA) and VM resizing based on real-time usage patterns, customers benefit from a responsive and cost-efficient autoscaling experience. This integration brings together:
- Resource-efficient applications: WebAssembly workloads with minimal overhead
- Ultra-high-density runtime: Fermyon Platform for Kubernetes’s ability to pack thousands of Wasm applications per node
- Dynamic infrastructure scaling: GKE Autopilot’s intelligent VMcapacity resizing and rapid scaling with an optimized HPA provisioning pods within seconds, supporting rapid linear scaling up to 1,000 HPA objects
Together, these technologies enable high resource utilization without sacrificing availability, delivering optimal performance while keeping costs in check.
See It in Action
What might this look like in the wild? Imagine you’re running a Shopify-like platform, hosting 1,000 unique websites for different merchants. Everything is running smoothly, with Fermyon Platform for Kubernetes efficiently handling the density of a thousand of Spin applications packed onto each node, while GKE Autopilot ensures that your infrastructure scales dynamically based on demand.
As Cyber Monday approaches, you anticipate these merchants will experience “viral” moments where they will receive an overwhelming amount of traffic. Here’s how GKE Autopilot and Fermyon Platform for Kubernetes rise to the challenge to handle the ballooning resource utilization.
A Surge in Traffic - A Welcome Challenge
As Cyber Monday kicks off around the world, users flock to websites. Within 5 minutes, the traffic hits an all-time high—seeing 10x more active users compared to the average daily active user count.
As we watch this unfold, we can see the Spin applications handling user requests for each of the merchant’s unique features, such as product catalogs, checkout processes, and image galleries, all smoothly without a drop in latency or increase in request failures.
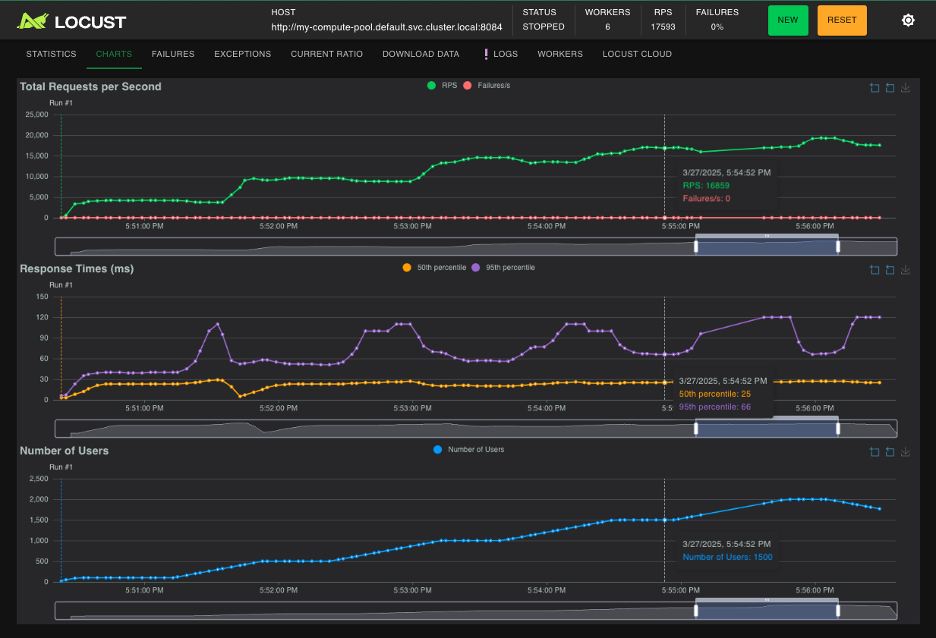
The Locust load testing UI shows how the system reacted to increasing levels of load. As the number of concurrent users and requests per second increased, 50th percentile latency remained stable and no 500s were ever returned. Each time a new replica of the compute pod scaled up, 95th percentile latency had a minor bump, with total response time taking at most 120ms. That includes the internal cluster network latency, Wasm instance cold start time, and execution time, still under the bare minimum cold start time for AWS Lambda.
The surge in requests triggers GKE’s optimized Horizontal Pod Autoscaler (HPA) to initiate 2x faster scaling for the affected application.
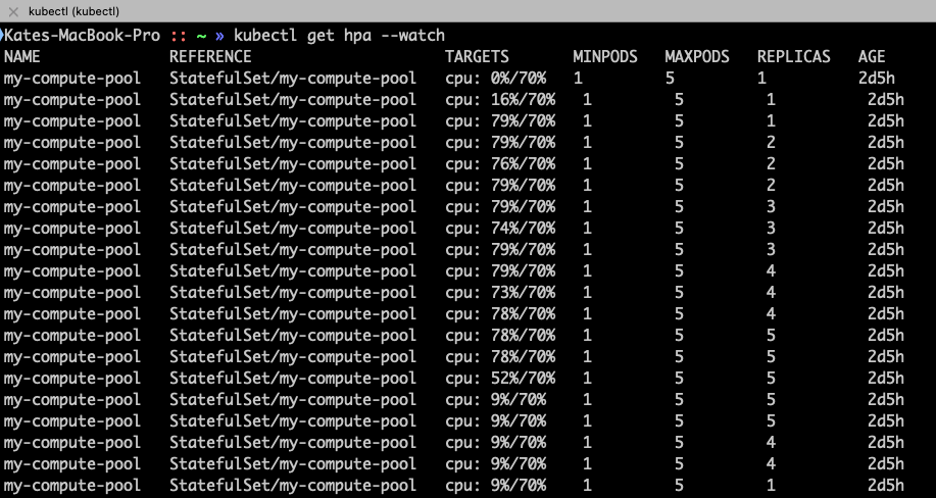
At the same time, GKE Autopilot begins resizing the underlying VMs to enable the pods to scale out up to 7x faster thanks to optimized compute infrastructure, increasing node resources to meet the demand. The system manages to keep up with the traffic surge without compromising on response time latency or service availability.
Resource-Efficient Scaling with Fermyon Platform for Kubernetes
While the various sites receive traffic spikes, the rest of the platform’s websites continue to operate normally. Thanks to Fermyon Platform for Kubernetes and GKE Autopilot’s adaptive node resizing, which allows for up to 1,000 Spin apps per node, the platform can handle this burst of activity without adding unnecessary overhead.
In the background, Fermyon Platform for Kubernetes’ high-density WebAssembly runtime keeps resource consumption to a minimum, with smaller footprints and faster startup times than traditional containers. Despite the massive influx of users, we’re able to keep costs in check and avoid the pitfalls of over-provisioning.
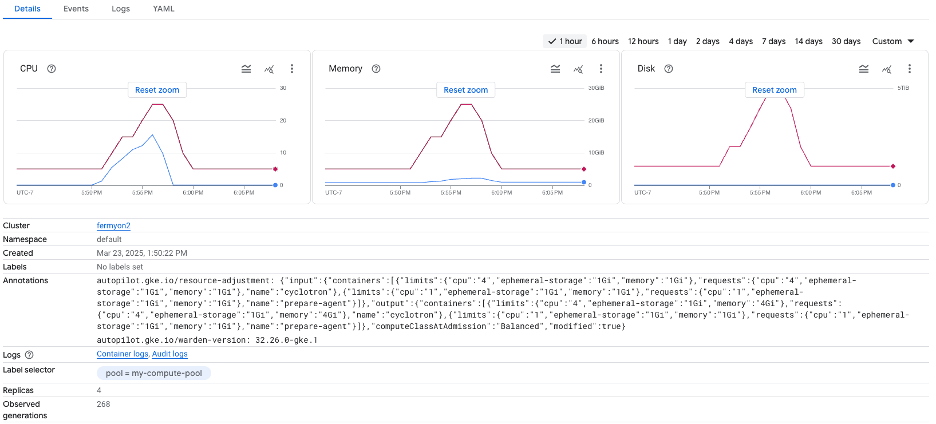
Scaling Down as Demand Normalizes
As Cyber Monday winds down, traffic to the sites begins to level out. With the viral moment over, as HPA reduces the number of pods used for the sites, GKE autopilot automatically resizes the VMs. Fermyon Platform for Kubernetes continues to serve all 1,000 Spin applications efficiently on the node.
This quick scaling down ensures that we’re not holding on to unnecessary resources, keeping costs low while maintaining the platform’s performance.
What’s Next?
Stay tuned as we walk through a real-world demonstration of how GKE Autopilot and Fermyon Platform for Kubernetes work together to deliver best-in-class autoscaling for WebAssembly-based workloads at Google Cloud Next.
By leveraging the power of Wasm, Kubernetes, and intelligent autoscaling, developers can build and deploy applications that are faster, more efficient, and more cost-effective—without the complexity of traditional containerized infrastructure.
Want to learn more? Reach out about getting started with the Fermyon Platform for Kubernetes today!