Spin Selective Deployments: A Leap Forward for Distributed Applications
 Matt Butcher
Matt Butcher
spinkube
spin
feature
deployment
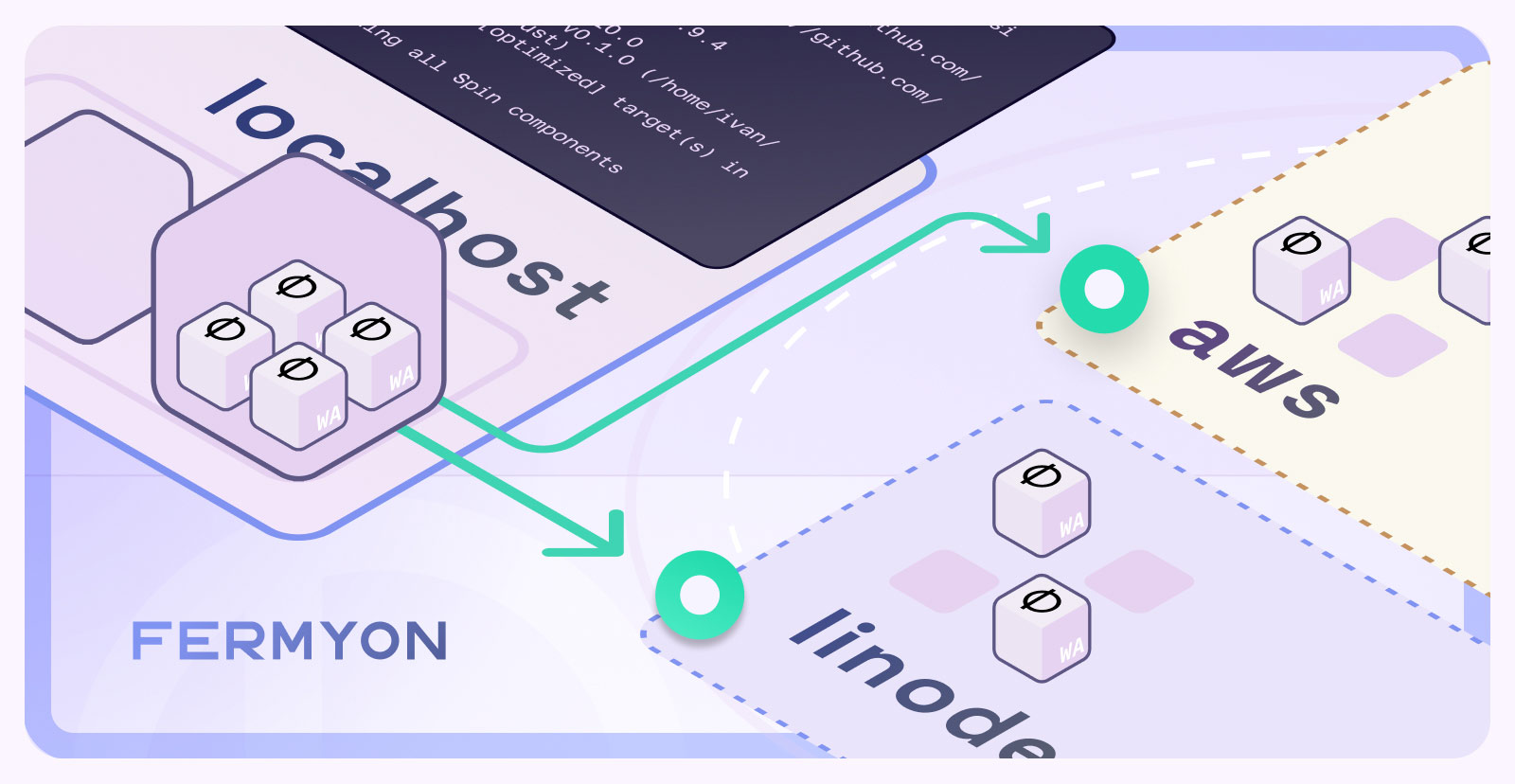
We’re excited to announce a new feature that has come to both Spin and SpinKube: Selective Deployments.
Compose a single codebase (even in multiple languages). Edit it in one project. Compile it with one build command. Test and run it locally as a single app. Then, at deployment time, break it down into microservices and distribute it across clusters, data centers, and networks. That’s what’s new in Spin and SpinKube, where we’ve taken distributed applications to a new level.
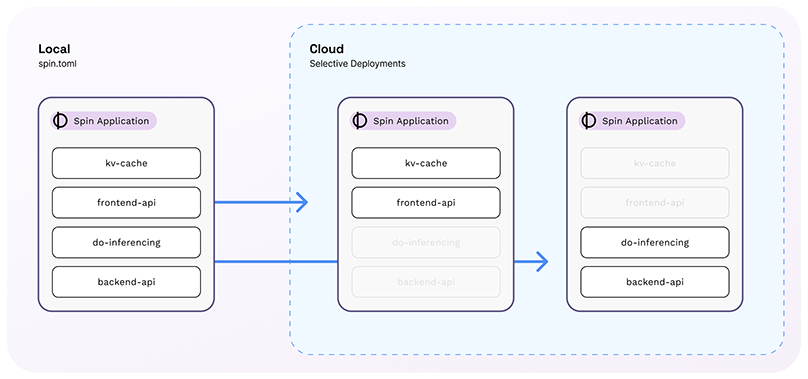
By combining Local Service Chaining in Spin apps with the ability to enable or disable individual components, you can develop distributed applications without even learning new tools or techniques.
You’ve heard us talk about the WebAssembly Component Model for the last couple of years. Now it’s time to demonstrate why it’s even more powerful than it superficially appeared. In addition to giving you the ability to write your applications in a truly polyglot way, the component model allows you to turn an application into a cluster of microservices.
With Spin 3 and the latest SpinKube, we’ve not only made this possible. We’ve made it easy. Write your apps as a collection of serverless functions. Call from one function to another in a way that feels like calling REST APIs even though calls are made in-process.
With SpinKube, you can deploy different components to different parts of your cluster (or even to different clusters altogether). To do this, you don’t even need to recompile. It’s just a matter of defining the configuration in your Kubernetes manifests. The distributed components communicate with each other over HTTP like microservices. Let’s dive into how this works, and how easy it is to build a single local app with Spin, and then deploy it as multiple microservices.
How It Works
Selective Deployment is done by combining three Spin technologies — two old, and one new:
- Local Service Chaining
- Variable management
- Component selectors (NEW!)
Local Service Chaining allows you to easily call one Spin component from another. Rather than having to work with WIT files and sophisticated toolchains, Local Service Chaining acts as a REST API, but without the network overhead. This means you can write Spin handlers that behave as microservices, but which are called in-process without ever opening a socket.
Spin also provides variable management that allows you to configure behavior at runtime. Variable substitution allows you to provide top-level variables that are then injected at runtime into various parts of your spin.toml file. This is a standard feature, but one that unlocks surprising possibilities.
Finally, Component Selectors provide both Spin and SpinKube a way of declaring at runtime which components in a Spin app should be activated for that particular installation. For example, an app may have five components, but a component selector may indicate that only two should be activated inside of the app instance at runtime.
Combining these three features, you can build a single application that has many components. These components can talk to each other using Local Service Chaining. By exposing configuration variables, you can allow runtime configuration that would change local service chaining to remote service calls. And by activating different component selectors, you can install the same app with different configurations in different locations. And, voila!, your local app is now a distributed multi-microservice application.
The diagram earlier in this article exhibits how one app can be split into two runtime instances, each running a different subset of components.
Building a Distributed Digital Experiences Platform
Here at Fermyon, we wanted to demonstrate how to build applications in this new way. So we built a digital experiences platform that provides a headless CMS, a traditional server-side frontend, and an administration interface, along with a variety of utilities like caches, QR code generators, and asset management.
Each piece of this application is written as a component. All the code is managed as a single Git project and edited in a single VS Code (or editor of choice) project, even though it’s written in a combination of languages. All of the components are built with a single spin build command and can be run monolithically using a single spin up command. Locally, we use the embedded SQLite DB and KV store. So literally there are no external runtime dependencies other than Spin. This makes it super easy for a developer to get up and running in moments.
For local development, the default Spin configuration uses Local Service Chaining to connect all of the microservices. So calling from one JS component to another Rust component looks like this:
// Frontend: Load a piece of content (by ID) from the CMS backend
async loadByPath(id: string): Promise<Tobi> {
let contentURL = Variables.get("cms_url"); // Load the URL from an app variable
let url = `${contentURL}/${id}`;
let res = await fetch(url); // A regular JS fetch call
//...
}
This code snippet is from the main website codebase. It calls into the CMS to load a particular piece of content.
In this small code snippet we can see how one service is calling to another in a way that looks like a REST API. And again, when we’re using Local Service Chaining, the call from one component to another is in-process with no networking at all. But an important detail above is that by using the Variables.get() call, we are loading the component reference at runtime.
We could just as easily replace the Local Service Chaining URL with a regular HTTP(S) URL. And in doing so, we’ve just replaced a REST-like interface with a true REST call. Spin understands that when this change happens, the request goes over the network instead of being routed in-process.
At first, this sounds weird. But the implications are actually profound. When you are in your inner loop writing code, you can write a bunch of components all side-by-side in the same project. When you spin up using Local Service Chaining, you can test them all locally in one single Spin process. It’s trivially easy to share SQLite and KV storage. And thanks to Spin’s flexible building process, you can even do this with the --watch flag and effortlessly move back and forth from component to component.
Contrast this with the experience of writing a regular microservice-based app. In that case, each microservice runs in its own process, is often tracked in its own Git repo, is compiled with its own toolchain, and has its own (often external) dependencies like databases. An app with just four or five microservices can take hours, if not days, to get running that first time on your workstation. Further, debugging is half internal, half external, as you have to navigate back and forth between different running process, often trying to match up tracing logs in different processes. This is exactly the opposite experience of what you get with Spin Selective Deployments.
Deploying Differently With Selective Deployments
When it comes to deployment, though, the contrast between traditional microservices and Selective Deployments is even more pronounced.
Using the Local Service Chaining strategy, your splits between components are dictated by good solid design decisions. But those choices do not carry over into the number of services you must run.
For example, in the digital experiences app discussed in the previous section, we created around a dozen components. But it was unnecessary (and not terribly performant) to then deploy a dozen different microservices. Instead, we grouped components into functional units:
- The front page logic, QR code generator, file server, and template renderer became the
frontend service
- The content repository, menuing system, and notification service became the headless CMS
backend service.
- And the administration interface, asset manager, and templates became the
admin service
Furthermore, some parts (like the authentication components) were deployed to all three services, while others (like a caching proxy) were enabled on the frontend even though they weren’t used (other than for testing) in the local development case.
In short, the matter of good architecture was kept distinct from the matter of runtime separation of concerns. Moreover, the decision about how to group components was largely left to the operational configuration. As the person responsible for deploying, I could decide which things belonged in which service. I could have, for example, moved the QR code generator to the backend without needing to even rebuild the deployment artifact.
That’s what Component Selectors provide: A way of specifying which components should be active for a given copy of the app. Deploy one single versioned artifact, but choose which parts of that artifact are turned on at startup. It’s a very elegant way to separate the developer concerns (build a well-architected app) from the operational concerns (run the app in the best way for your own infrastructure).
Taking It To The Edge
There is one more interesting aspect to this combination of technologies: There’s no reason why all of the components have to run on the same machine, the same cluster, or even the same cloud provider. At one point, I deployed a single copy of this application such that:
- One copy of the frontend was running at a datacenter in Germany
- Another copy of the frontend was running at a datacenter in Seattle
- And a third copy was running in Dallas
- While the headless CMS ran only in Dallas (and the remote frontends had proxy caches to speed delivery)
- And the admin interface was deployed on a small bespoke server elsewhere, so that it was not a target for hackers
If you are keeping track, that means that with one binary artifact, we deployed to four data centers (on two flavors of Kubernetes) using three different “expressions” of the same application (frontend ,backend, and admin). All of this was still managed in one Git repo with one CI pipeline.
Here’s a more simplified representation of that same concept. Building on the diagram above, we can imagine a case where the same Spin app is configured differently for two different target environments.
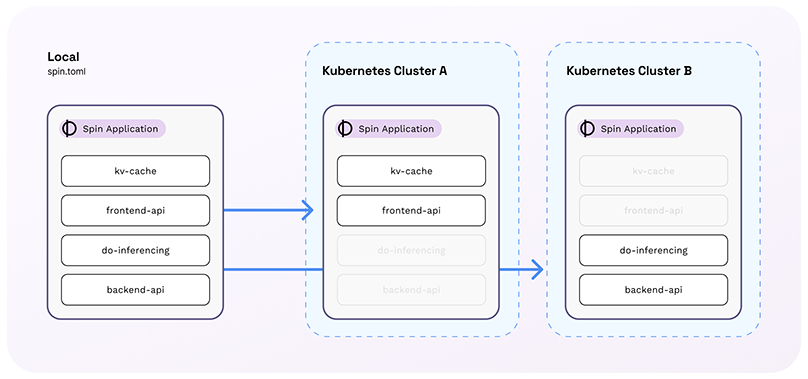
The app can be split so that the frontend is pushed as close to the user as possible (along with a performance enhancing cache) while the rest of the app is nestled in a central datacenter. This same app that the developer manages in a single git repo and builds with a single build command is now being spread, at runtime, across multiple geographically and functionally disparate environments — all without so much as a re-compile!
Learn More
Selective Deployment is a new feature of Spin 3 and SpinKube. Combining Local Service Chaining, variable management, and Component Selectors, it is possible to build applications that function as a single service at development time, but can later be split into finer-grained microservices. Out of this, you get:
- A vastly better developer experience for building microservice-style apps
- The ability to build polyglot apps in a single codebase
- Flexible deployment options that let the platform engineering decide how best to run the application
We’ll be demonstrating the power of splitting apps via Selective Deployments at KubeCon in Salt Lake City. From developer experience to day two ops, Selective Deployment allows you to easily build a new generation of distributed applications.