How We (Accidentally) Wrote the Ideal AI Platform
 Matt Butcher
Matt Butcher
spin
cloud
ai
fermyon
gpu
platform
When we launched Fermyon, we aimed to create an optimal foundation for the next generation of serverless applications. This article highlights a recent technological leap and explains how we (accidentally) wrote the ideal AI platform.
Our original goal, at Fermyon, was to build a new wave of cloud computing that would make the ideal foundation for a new generation of serverless applications. Serverless functions are so easy to write, but existing platforms are slow and clunky. We wanted to start with a more elegant developer experience that resulted in better-performing serverless apps.
We were pleasantly surprised when we realized that the design decisions we had made along the way made Fermyon a great developer platform for Artificial Intelligence (AI) workloads as well. Specifically, as we looked around the emerging AI ecosystem, we observed the following:
- Graphics processing unit (GPU) time is expensive, but you need GPUs to use an AI model quickly; GPUs have many parallel cores that allow efficient processing of AI tasks. The parallelism makes them faster, when compared to central processing units (CPUs).
- Writing code specific to one architecture makes it hard to build locally and then deploy to the highest-powered environments.
- To run AI workloads, developers were pushed into a dilemma: Add yet another external service provider to the mix or stand up their own low-level infrastructure.
In short, AI was making developer life even more difficult. But all of those points were problems we’d been focused on when building Fermyon Spin and Cloud. We just needed to do a little bit of work to add AI inferencing to the existing toolbox.
And the first inkling of this realization hit at an airport in Germany.
It All Started on the Way to India
Radu and I were traveling together on our way to India. We met at Frankfurt Airport. While we were sitting around waiting for the flight to board, Radu pulled out his laptop and said, “I have been playing with some Large Language Model (LLM) inferencing code.” He showed me a quick demo of some (actually kind of slow) inferencing written in Rust and using the Alpaca LLM. “I downloaded a few models to play around with on the flight,” he said, “I think I can integrate inferencing into Spin.”
When Radu says something improbable, I usually respond with “Sure. Sounds good.”
We boarded the airplane and took off. As soon as we hit cruising altitude, Radu pulled out his laptop and said, “I’m going to give this a try.” I don’t code on planes. I sleep. Before Radu had started up NeoVim, I was out like a light.
Four hours into the flight, I woke up. Radu was staring down at me. “Oh good! You’re awake! I have a demo to show you!” And there, somewhere over the ocean between Frankfurt and Bangalore, Radu demoed AI inferencing on Spin. It was slow, but it was also really cool. Write your inferencing code, compile it to WebAssembly, and run it locally in Spin.
As we journeyed around India, Radu kept improving the code, and we kept talking. The more we talked about what we were building, the more we realized how powerful it was:
- It wouldn’t be hard to add GPU support to Fermyon Cloud. With Spin, you can build your code locally, run it locally on the CPU for testing, and then deploy it to Fermyon Cloud to use its powerful GPUs. Wasm really is “write once, run anywhere”.
- Unlike the usual AI inferencing platforms, our Serverless AI would start up in milliseconds, have an AI model queued in less than a second, run on GPUs, and then shut down. Instead of paying for long startup times and always-running nodes, we were cutting the time down to just the time it takes to do each inference during a request.
- Running on high-end GPUs in Fermyon Cloud, the inferencing itself would be vastly faster than on a local laptop.
- Most AI services are bare-bones and require you to write your code on one platform and do your inferencing on another. You’re either chaining together REST APIs or building your own platform. But Fermyon Cloud comes with built-in Key Value storage and an SQLite-based relational database (DB). In other words, we already had the key pieces for a full developer platform.
We came back from India and pitched it to the rest of our superstar team. And they loved it. Now, less than two months later, we’ve rolled out our Fermyon Serverless AI service.

Getting Started is Easy… and Free
There are two halves of working with AI. One is training models, and the other is querying those models (inferencing). While training is an expert-level endeavour, AI inferencing is easier than writing SQL. Inferencing is the part that we use to build applications. So, Fermyon Serverless AI is entirely focused right now on the inferencing half. We need GPUs, one or more models, and a place to execute some code to do inferencing. That’s what Fermyon Serverless AI provides.
GPUs are expensive. But if we can time-slice GPU usage down to the millisecond level, swapping applications as fast as we can, then even the costly GPU is suddenly economical to run. We’re so confident in our efficiency that our first release is free to use. We’ll introduce pricing later, but we’ll always have a free tier.
If you want to try this out, create a Fermyon Cloud account (all you need is your GitHub handle) and add yourself to the early access list. We’ll enable the new AI inferencing feature on your Fermyon Cloud account. You’ll also need to be running the canary version of Spin.
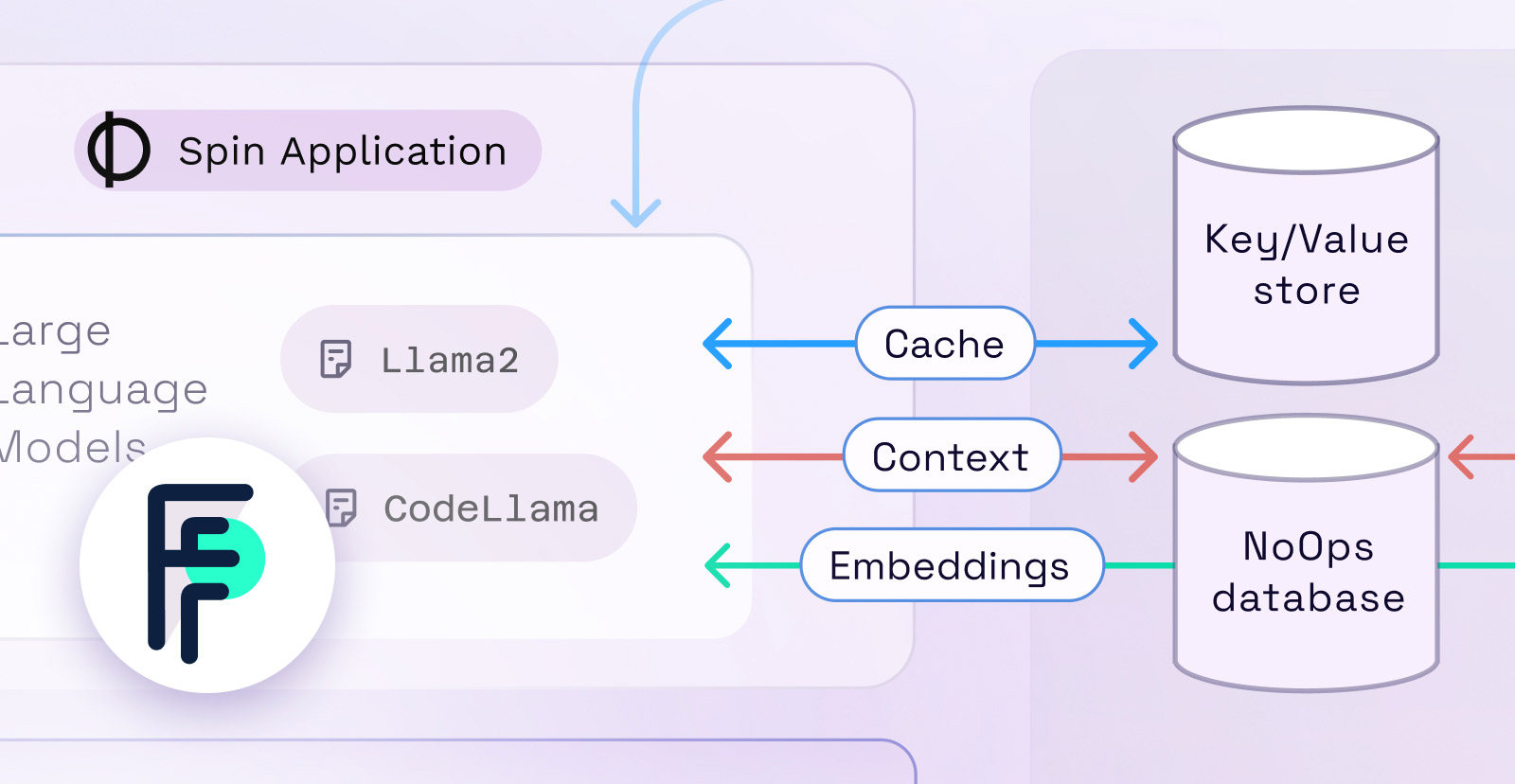
For this first launch, Fermyon Cloud has two models built-in: LLaMa2 for generating text and CodeLlama for working with code.
In the future, you’ll be able to upgrade your account to generate more tokens or use different models. But if that’s something you need to do now, reach out to us today.
You Don’t Need External DBs
AI is about more than models. Storing context, tags, and embeddings is critical for getting the most out of an LLM. To seamlessly work with all these elements, developers can utilize Fermyon’s built-in data services like Key Value Store and SQLite Database.
For example, you can store your embeddings in Key Value Store or the SQL Database. Cache results in Key Value storage. Keep context in Key Value Store for doing semantic searching. All of this is easy (and fast) without ever needing to add an external service.
All three of these services (KV Store, SQL DB, and AI inferencing) are built in a NoOps style — you don’t have to manage anything locally or remotely. No provisioning, no credentials or permissions to manage, no TLS certificates or connection strings… all of that is handled for you (in a secure way) by the host runtime. Development is as simple as using the language APIs.
How Does It Work?
One of our design goals for Spin and Fermyon Cloud since the beginning has been to maximize resource utilization. Originally we were thinking of this in terms of memory and CPU, but GPU is just one more resource. On the cloud side, all we needed to do was extend our resource managing to one more piece of hardware.
Fermyon Cloud runs a massively multi-tenant version of Spin called LHC (yup, another physics joke). A single LHC instance may run upwards of 1,500 serverless apps. Workloads are scheduled onto one of our LHC instances by Nomad. LHC is designed to maximize CPU and memory.
Due to the nature of CPU versus GPU usage, it didn’t make sense to have one service that managed both CPU and GPU usage, mainly because it didn’t make sense to have GPUs on every one of the LHC servers. (That would be too much GPU). The best thing to do, we decided, is to split CPU and GPU management.
Separately from the LHC cluster, we run a GPU cluster on Civo’s cloud. We have a service there called Muon (again, physics joke) that schedules work onto the GPUs.
When a Spin app runs an AI inferencing operation, a request is queued to Muon, which runs the inference on the first available GPU and then returns the results. Typical inferences run for between a few seconds and perhaps a few dozen seconds. While many other systems may take well in excess of 90 seconds to even start up the necessary process or container, Muon can execute dozens of inferencing requests from different apps in that same window of time. As soon as one app has finished its inference, another is shuffled onto the GPU. In an interactive app such as the popular chat form, Muon can interleave different apps between prompts. This is far more efficient than the usual model of locking a GPU to a single application for that application’s entire session.
Loading and unloading models is another slow aspect of many AI services. Once more, Muon provides a way to work around this, as it can keep models loaded in memory in an LRU style, meaning the most frequently used models can load instantly without reading from disk. As we launch, we initially support the LLaMa2 and Code LLaMa models, but we’ll be adding more and even want to introduce support for you to bring your own model.
Conclusion
When we started Fermyon, we set out to build a new wave of cloud computing focused on supersonic startup times, great security, and a write-once, run-anywhere binary format. And we wanted to do all of this inside of a serverless system that was genuinely a pleasure for developers to use. AI inferencing is a new style of workload, but one that benefits tremendously from these features. We’re excited about the new things that will be built with AI inferencing. That’s why we built the new Serverless AI tools.
If you want to get started, sign up for early access. Then head on over to the documentation to get started, or take a look at some examples. As always, if you want to chat or ask questions, don’t hesitate to join us on Discord.